
Welcome to Junjie Fei’s Homepage!
I am currently a second-year PhD student at King Abdullah University of Science and Technology (KAUST), advised by Prof. Mohamed Elhoseiny. I am also a Research Scientist Intern at Meta AI, hosted by Dr. Chenchen Zhu, where I work on advancing multimodal reasoning.
Prior to KAUST, I received my BS and MS degrees from Chongqing University and Xiamen University, respectively. I also gained research experience as a visiting scholar and research assistant at SUSTech VIP Lab and KAUST Vision CAIR. For more details, please refer to my CV.
My current research interests lie in vision-language multimodal learning. If you’re interested in collaborating, feel free to contact me at junjiefei@outlook.com or junjie.fei@kaust.edu.sa.
News
- [2025/09] One paper has been accepted by NeurIPS 2025!
- [2025/09] Joined Meta AI as a Research Scientist Intern!
- [2025/06] Two papers have been accepted by ICCV 2025!
- [2025/02] One paper has been accepted by CVPR 2025!
- [2024/08] Joined KAUST as a PhD student!
- [2023/07] One paper has been accepted by ICCV 2023!
- [2023/04] Project Caption Anything is publicly released!
Research
(* equal contribution)
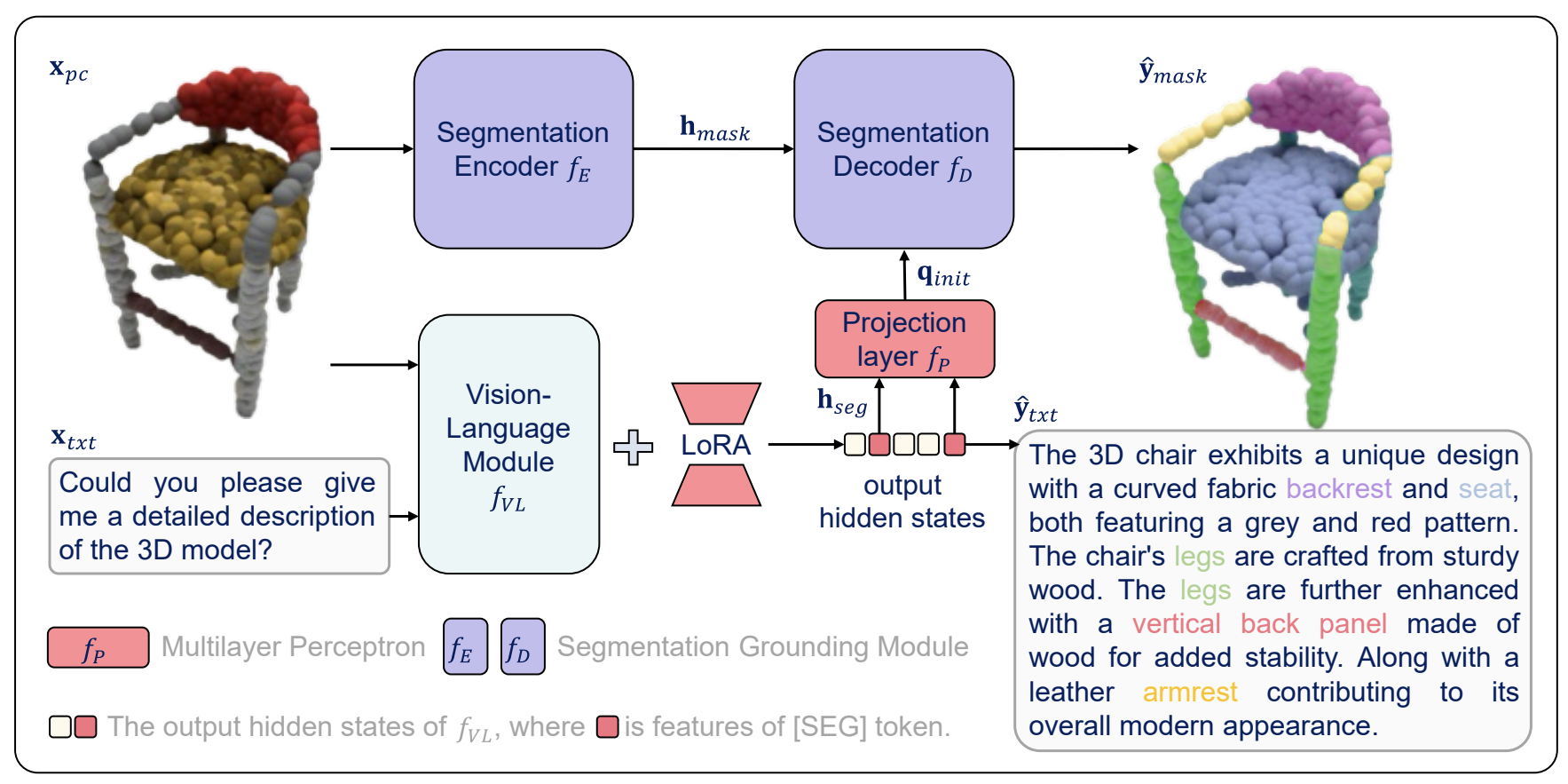 | Mahmoud Ahmed*, Junjie Fei*, Jian Ding, Eslam Mohamed Bakr, Mohamed Elhoseiny ICCV, 2025 project / paper Kestrel is a part-aware point grounding 3D MLLM, capable of comprehending and generating language and locating the position of the object and its materials at the part level. |
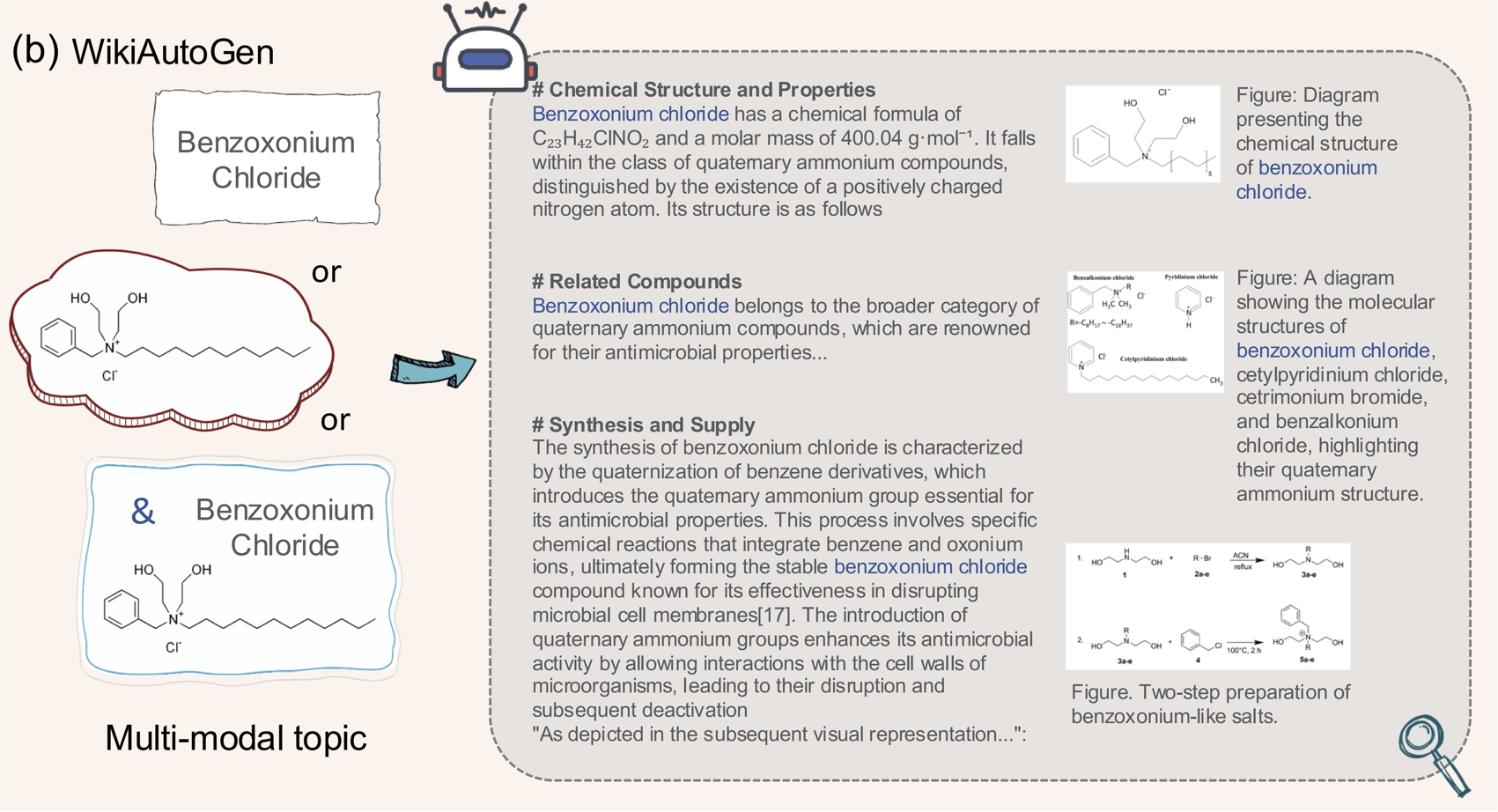 | Zhongyu Yang*, Jun Chen*, Dannong Xu, Junjie Fei, Xiaoqian Shen, Liangbing Zhao, Chun-Mei Feng, Mohamed Elhoseiny ICCV, 2025 project / code / paper WikiAutoGen is a novel system for automated multimodal Wikipedia-style article generation, retrieving and integrating relevant images alongside text to enhance both the depth and visual appeal of the generated content. |
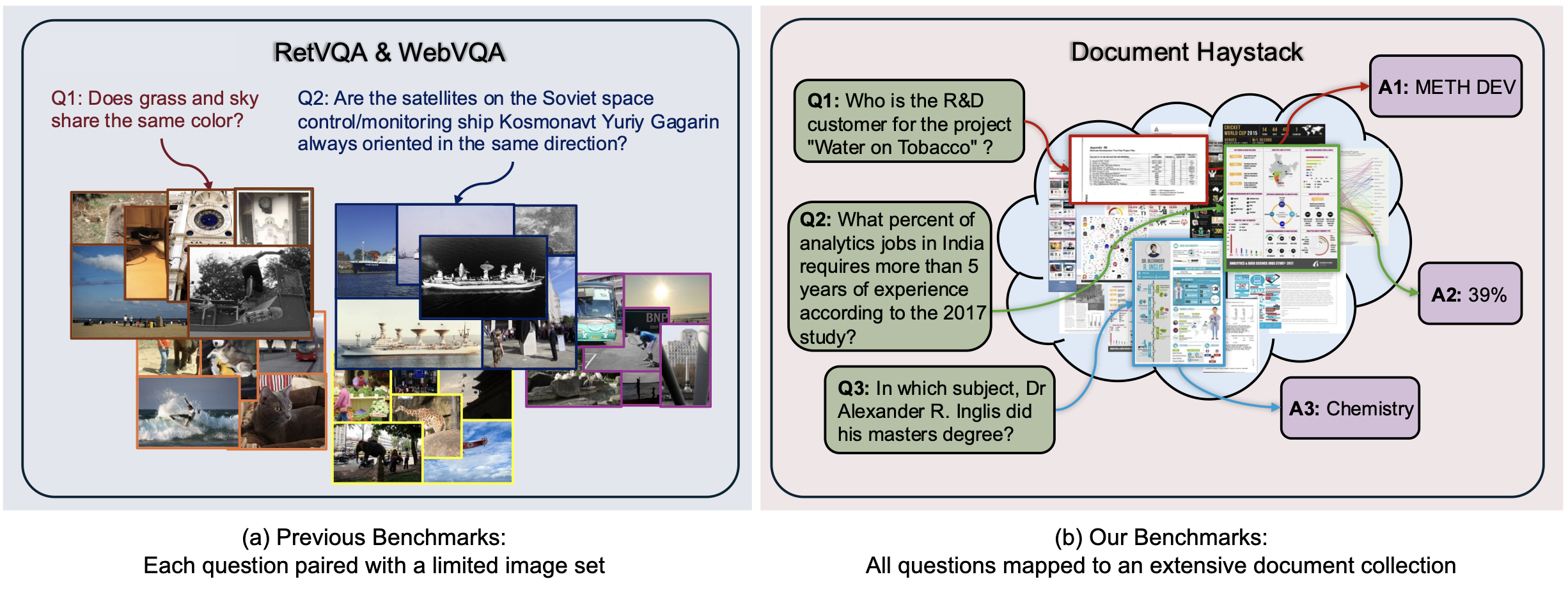 | Jun Chen*, Dannong Xu*, Junjie Fei*, Chun-Mei Feng, Mohamed Elhoseiny CVPR, 2025 code / paper / benchmark The Document Haystack Benchmarks aim to evaluate the performance of VLMs on large-scale visual document retrieval and understanding. |
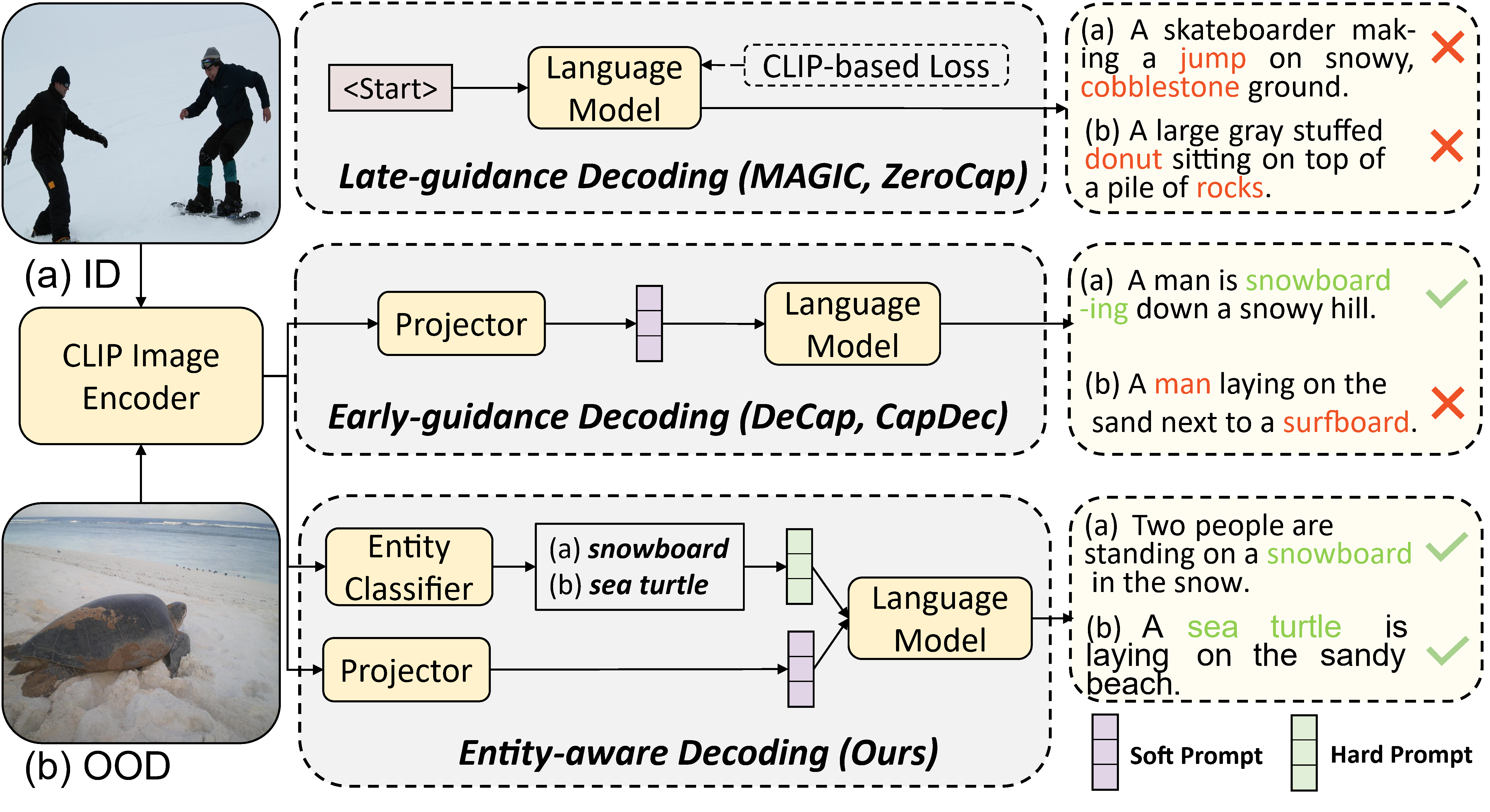 | Junjie Fei*, Teng Wang*, Jinrui Zhang, Zhenyu He, Chengjie Wang, Feng Zheng ICCV, 2023 code / paper Improving the transferability of zero-shot captioning for out-of-domain images by addressing the modality bias and object hallucination that arise when adapting pre-trained vision-language models and large language models. |
 | Teng Wang*, Jinrui Zhang*, Junjie Fei*, Hao Zheng, Yunlong Tang, Zhe Li, Mingqi Gao, Shanshan Zhao arXiv, 2023 code / paper / demo Caption Anything is an interactive image‑to‑text generative tool that can generate diverse descriptions for any user-specified object within an image, providing a variety of language styles and visual controls to cater to diverse user preferences. |
Academic Services
Conference reviewer for NeurIPS, ICLR, ICML
Journal reviewer for IEEE TMM, Neurocomputing